Господа, с моей точки зрения (я занимался верификацией много лет и мои верификационные IP использовались в MIPS, Apple (клиент компании Denali, сейчас Cadence) и других компаниях), так вот, с моей точки зрения, это не самый удачный пример. Я могу разобрать его по строчкам, но главная проблема:
Когда совершенно новый человек на это смотрит, у него возникает вопрос "а зачем городить весь этот огород для верификации модуля, у которого один вход, один выход и все данные передаются последовательным burst-ом? Зачем для этого все эти транзакции, порты, scoreboard итд? Почему бы не написать один task на верилоге длиной 30 строк, который будет в цикле класть на вход данное и проверять выход?"
Так вот, чтобы такого вопроса не возникало, в примере должны быть:
1. Или конвейерные транзакции, например как на шине AXI.
2. Или транзакции с ответами, которые выходят в другом порядке, чем запросы.
3. Или транзакции с interleave.
4. Или несколько источников транзакций.
5. В рандомизации должны быть интересные условия в constraints, а не просто de-facto эквивалент нескольких вызовов функции $urandom.
6. В примере нужно чтобы где-нибудь были covergroups, потому что рандомизация без functional coverage сразу вызывает вопрос "а как мы проверим, что наши случайные тестs покрывают все случаи, требуемые по функциональной спецификации на DUT? Давайте лучше делать directed тесты и constrained random только как дополнение".
Иллюстрация: транзакции на шине AXI - адрес новой транзакции может оказаться на шине раньше чем данные предыдущей транзакции - вот здесь конструкция драйвер / монитор / scoreboard упрощает верификацию, а не усложняет ее, как с кодом в вашем примере:
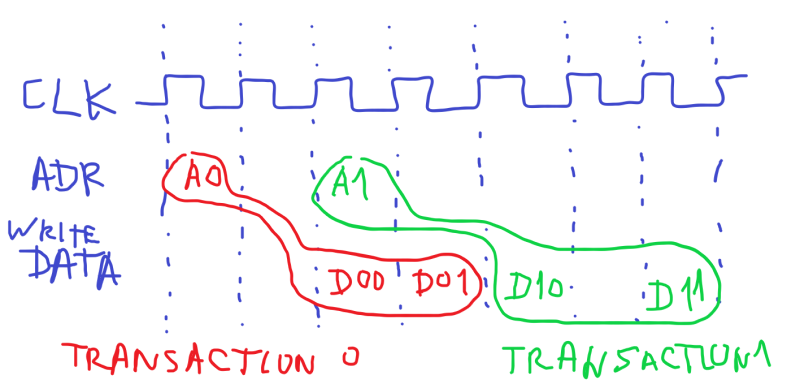
Еще более интересные случаи, когда и адрес, и данные второй транзакции оказываются целиком между адресом и данными первой транзакции, или когда транфсеры данных второй транзакции переплетаются (interleave) с данными первой транзакции. Вот тут действительно нужен scoreboard (хотя эти случаи не годятся для вводного примера).
*** Поскольку прямой перевод слова «scoreboard» (табло) здесь не очень подходит, далее будет использоваться английское написание. ***
Кстати, а вы знаете, почему scoreboard так называется ("табло")? Потому что при верификации блоков посложнее в нем действительно хранится таблица транзакций in-flight ("в полете") которые могут заканчиваться не в том порядке, в котором выходили запросы. В рассматриваемом случае таблица состоит из двух очередей, поэтому для нее название "табло" действительно не очень подходит, но для примера с конвейерными транзакциями (не говоря уже об out-of-order и interleave) это совершенно подходящее название - для них действительно нужно строить табло с transaction ID.
Да, знаю, что создать простой и убедительный пример трудно. Но читателя нужно убедить, что все эти методики реально облегчают жизнь, а ваш пример в этом не убеждает. К сожалению 90%+ примеров в интернете и книжках тоже страдают этой проблемой.
В частности упомянутая книжка Ray Salemi - это просто слабая книга. Демонстрировать UVM на примере TinyALU - это примерно как агитировать за использование C++ с помощью следующего кода для сложения 2+2:
Number a, b, c;
a = new Number (2);
b = new Number (2);
c = new Number ();
c.setValue (a.getValue () + b.getValue ());
cout << setw (4) << c.getValue ();
Читатель на это посмотрит и скажет: "ой, спасибо, я лучше вернусь к своему питончику, где я могу написать print 2+2".